세계 최초 사용자 페르소나(Persona)와 외부 지식 활용하는 데이터셋 구축
올해 10월 '전산언어학회 COLING 2022'서 고려대와 공동 워크샵 개최
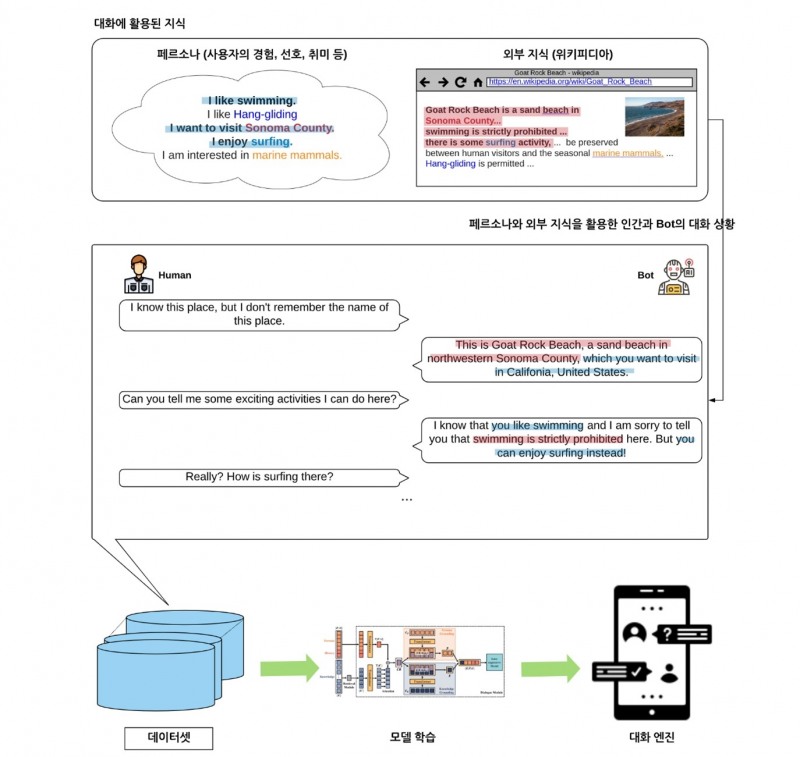
'FoCus Dataset'은 사용자 개인의 페르소나(Persona)와 외부 지식을 모두 활용하는 세계 최초의 AI 대화 데이터셋이다. 약 8000여 개의 광범위한 주제를 다룬 1만5000개 이상의 대화로 구성돼 있다.
'FoCus Dataset'은 초거대 언어 모델을 사용하지 않고도 같은 성능의 대화 기술 구현이 가능한 것이 특징이다. 현재 일반적인 대용량 언어모델은 학습과 추론에 많은 비용이 소요됨에도 불구하고, 실시간 지식과 개인의 경험을 반영하는데 한계를 나타내고 있다.
공동연구팀은 지난 2월 세계 최고 권위의 인공지능 학회 'AAAI 2022'에서 해당 연구 논문을 게재 및 발표했다. 오는 10월에는 세계 전산언어학회인 'COLING 2022'에서 데이터 활용 경진 대회(Shared Tasks)를 비롯한 연구 성과를 공유하는 워크샵(The 1st Workshop on Customized Chat Grounding Persona and Knowledge)을 고려대와 공동 개최한다.
이원희 기자 (cleanrap@dailygame.co.kr)